RePrompt: Automatic Prompt Editing to Refine AI-Generative Art Towards Precise Expressions (2023)
ABSTRACT
- AI generated images가 얼마나 context와 emotion을 정확히 반영하는지 불분명함
- → 이에 AI generated images의 emotional expressiveness를 연구하고, RePrompt를 개발함
- RePrompt: AI generated images의 보다 정교한 expression을 위한 automatic text refine method
- text feature들을 선정 → proxy model을 훈련시켜 각 feature들이 AI generated images에 미치는 영향을 알아봄 → text prompt adjustment의 rubric을 만듦
- 특히 negative emotions에서 emotional expressiveness가 significantly improve함을 보임
- text feature들을 선정 → proxy model을 훈련시켜 각 feature들이 AI generated images에 미치는 영향을 알아봄 → text prompt adjustment의 rubric을 만듦
INTRODUCTION
PRIOR WORKS
- 서로 다른 rephrasing of prompt using same keywords는 AI generated images 결과물에 있어서 큰 영향을 미치지 않음
- five types of prompt modifiers
- subject terms, style modifiers, quality boosters, repetitions, magic terms
→ 여전히 emotion expression에 대해서는 불분명함
- 따라서 보다 복잡한 형태의 prompt를 활용한 emotion expression을 연구함⇒ 기존의 descriptive prompt들과 차이점을 가짐
- (일상생활에서의 emotion expression and sharing - ex. 문자, SNS 등)
RATIONALE
- emotional intelligence는 AI의 intelligence를 평가하는데 있어 필수적인 요소임
- 인간들은 자신의 감정을 표출하고자 하는 본능을 가지고 있음
- visual art (그림이나 사진 등)은 글자로 표현할 수 없는 것들을 가지고 있음
- → 일상생활 시나리오와 text-to-image generative AI 사이의 연결을 통해 글자를 통한 감정 표현과 이미지를 통한 감정 표현 사이의 보다 자연스러운 transmission이 가능하도록 함
-

METHODOLOGY
- Interview study
- 비전문가들이 AI generated images를 어떻게 이해하는지
- 결과물을 improve하기 위해 어떻게 prompt를 수정하는지
- XAI를 이용해 어떻게 이 과정을 자동화할 지에 대한 방안을 개발
CONTRIBUTION
- emotion expression의 측면에서 비전문가들이 AI generated images를 어떻게 이해하는지, 결과물을 improve하기 위해 어떻게 prompt를 수정하는지에 대한 조사 결과
- RePrompt 개발
- text feature들을 선정 → proxy model을 훈련시켜 각 feature들이 AI generated images에 미치는 영향을 알아봄 → text prompt adjustment의 rubric을 만듦 → 자동화함
- 다른 prompt engineering 방식들과 비교 및 평가하는 simulation & user study를 통해 특히 negative emotion의 측면에서 improve함을 보임
- 해당 방식의 design implications, generalization, potential application을 제시함
RESEARCH QUESTIONS AND METHODOLOGY
INTERESTS
- emotional text를 프롬프트로 하여 text-to-image generative model이 얼마나 이미지를 잘 만들어내는가
- 어떻게 이를 improve할 것인가
MODEL AND DATASET
- Text-to-Image Models
- VQGAN-CLIP: 10,000개의 이미지 생성 후 proxy model 훈련에 사용
- DALLE 2: User Study에 사용될 이미지 생성에 사용
- VQGAN과 달리 diffusion model 사용, 더욱 실사에 가까운 이미지 생성, filtering mechanism 가지고 있음 (그러나 API로는 없어서 improper text를 피하였음), faster (실시간 인터랙션에 적합)
- Emotional Text Dataset
- EmphatheticDialogues: emotion labels, situation texts를 활용했음
- Twitter Dataset과 달리 품질이 좋음 (오타 없음 등)
- EmphatheticDialogues: emotion labels, situation texts를 활용했음
💡 RQ1: How would laypersons perceive the AI-generated images regarding emotional expressiveness and strategically refine the text prompts to improve image generation?
- Interview (비대면 온라인 줌 녹화, Think-Out-Loud)
- prepared emotional text를 이용해서
- 비전문가들이 AI generated images를 어떻게 이해하는지
- 결과물을 improve하기 위해 어떻게 prompt를 수정하는지
- 수정 전략 파악
- prepared emotional text를 이용해서
EMOTIONAL TEXTS
- 200개 텍스트, 10가지 감정 (joyful, sad, angry, afraid, lonely, excited, proud, surprised, trusting, anxious)
- text-emotion alignment가 낮거나 DALLE2의 방침에 따라 이미지 생성이 금지되어 있는 단어가 많이 포함된 텍스트들을 가진 감정을 제외함
- 결과적으로 146개 텍스트와 이미지를 활용하였음
- text-emotion alignment가 낮거나 DALLE2의 방침에 따라 이미지 생성이 금지되어 있는 단어가 많이 포함된 텍스트들을 가진 감정을 제외함
PARTICIPANTS AND DATA COLLECTION
- 19명 (남성 8, 여성 11, 19-39세)
- 소요 시간 40-60분, 10싱달 지급
PROCEDURE
- 실험자가 prepared emotional text를 제공, DALLE2 웹사이트 화면 공유
- 피험자는 아래 과정을 10회 반복
- 텍스트 프롬프트를 읽고 text-emotion alignment를 구두로 평가 (0-100)
- (ex. “how much do you think this text expresses the [emotion label, ex. lonely] emotion?”)
- 생성된 이미지 4개 관찰
- 구두로 ITA(image text alignment) & IEA(image emotion alignment) 평가(IEA; ex. “how much do you think the images express the [emotion label, e.g., lonely] emotion?”)
- (ITA; ex. “how much do you think the images express the text?”)
- 프롬프트 수정 후 1-3 반복
- 이후 피험자는 자신의 프롬프트 수정 전략을 설명함
RESULTS
- Participants’ Understandings of the Text-to-Image Model
- AI는 복잡하고 추상적이기보다는 단순하고 구체적인 설명을 더 잘 이해함
- 특정 concept를 이해하지 못하기도 함
- ex. 영화 제목, 닌텐도 스위치 등
- 객관적인 설명을 더 잘 이해하는 것처럼 보임
- 언제, 왜 예상대로 이미지를 만들어내지 못하는지 이해하기 어려운 경우가 있었음
- → 반복되는 실패는 bad UX로 이어짐
- Participants’ Editing Strategies
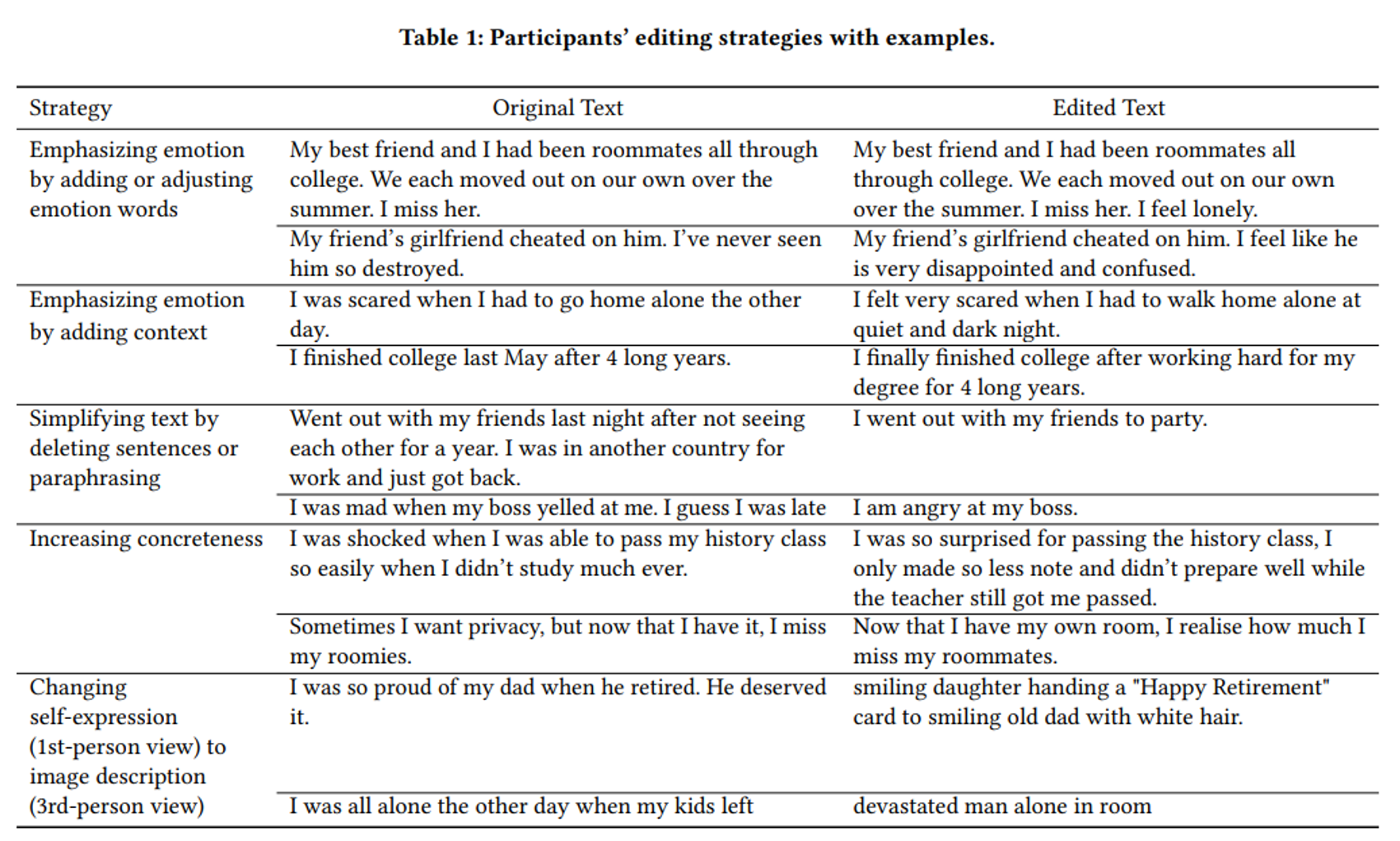
- 감정과 Key concept를 간결하고 명확하게 작성하기
- elements와 description을 구체적으로 만들기
💡 RQ2: How can text prompts be automatically refined to generate better images regarding emotional expressiveness?
- RePrompt: XAI 기반의 자동 프롬프트 엔지니어링 method
- 어떤 prompt feature가 더 나은 이미지를 생성해내는가 이해
- word level text feature 선택 (RQ1으로부터)
- 이를 바탕으로 머신러닝 모델을 학습시켜 AI generated images의 품질을 예측
- 이를 자동화할 수 있도록 word level features를 조정하는 rubric 만듦
- 프롬프트 revise 자동화
- 어떤 prompt feature가 더 나은 이미지를 생성해내는가 이해
FEATURE CURATION
- 텍스트 프롬프트 내 어떤 feature가 어떻게 결과물에 영향을 미치는가
- human-interpretable prompt engineering methods의 개발을 목표로 하므로 직관적이고 easy-to-adjust한 features를 선택하였음
- feature design
- 텍스트 프롬프트 내 각 단어에 대해 part-of-speech (POS)를 identify
- 각 POS type에 대해 count occurrences (ex. 명사의 개수)
- 각 POS type의 concreteness score of words 평균을 계산 (ex. mean concreteness of adjectives)
- word concreteness from the English word concreteness dataset
- 40,000개의 잘 알려진 영단어의 word concreteness를 포함하고 있는 데이터 셋
- 총 20 features 를 고려함

- word concreteness from the English word concreteness dataset
- word-level features: 쉽게 이해하고 조정할 수 있음 (단어의 삭제, 추가, 재배치로 feature values를 조정할 수 있음)
- features of word counts: text complexity를 보여줌
- features of word concreteness: text concreteness를 보여줌
- 이제 curated features를 quality of AI-generated images와 연결할 모델이 필요함
CLIP SCORE FOR IMAGE QUALITY ASSESSMENT
- CLIP: 텍스트와 이미지 쌍 사이 cosine similarity를 계산하여 semantic closeness를 알 수 있음
- CLIP은 junk input을 구분하지 못하므로 이에 유의하여야 함
- 이를 활용해 ITA, IEA를 계산함
- ITA: image and text
- IEA: image and emotion label
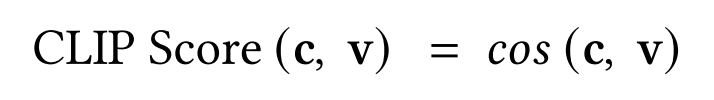

PROXY MODEL AND FEATURE ANALYSIS
- 이미지의 품질을 예측하고, 어떤 feature들이 이미지 생성에 영향을 미치는지 이해하고자 함→ 따라서 proxy model을 이용해서 이미지 품질을 측정하기로 함
- → XAI 이용 시 모델을 여러 차례 call해야 하는데 이는 생성형 AI 모델에 부적합함
- proxy model을 이용한 이미지 품질 측정
- training data
- 10,000개의 텍스트, 32개의 감정 이용 (EmpatheticDialogues)
- VQGAN-CLIP model을 이용해 텍스트 당 이미지를 하나씩 생성
- 텍스트 샘플 사이즈를 5,000 → 8,000으로 증가시켜 나감
- API access가 없어서 DALLE 2를 이용하지 않음
- 이 점이 평가에 영향을 미치지 않았음을 이후 증명함
- CLIP scores 계산
- VQGAN-CLIP model을 이용해 텍스트 당 이미지를 하나씩 생성
- 10,000개의 텍스트, 32개의 감정 이용 (EmpatheticDialogues)
- 점수 예측을 classification problem으로 모델링 함
- 여러 기계 학습 모델(Random Forest, XGBoost, LightGBM, Multi-layer perceptron)을 활용하여 IEA와 ITA를 개별적으로 예측
- text features와 classification labels를 사용함
- LightGBM이 best performance를 보임
- with 5-fold cross-validation (AUC = 0.60 for IEA, AUC = 0.73 for ITA)
- 생성된 이미지의 감정 표현력을 향상시키는 것이 주요 목표이므로 IEA 예측 모델에 초점 → automatic text editing의 rubric을 도출하는 데 사용
- 여러 기계 학습 모델(Random Forest, XGBoost, LightGBM, Multi-layer perceptron)을 활용하여 IEA와 ITA를 개별적으로 예측
- training data
FEATURE ANALYSIS BY MODEL EXPLANATIONS
- 어느 features가 중요한지 SHAP explanations을 이용해 확인
- SHAP (SHapley Additive exPlanations): 유명한 XAI technique
- 모델로부터 각 feature를 제거하고 performance의 감소 여부를 확인하며 features의 중요도를 계산
- 각 instance마다 feature importance explanation을 제공 → 집계하여 overall global explanation을 보일 수 있음
- Partial Dependence Plots (PDPs)
- value range에 대한 feature contribution의 분포를 제공함
- target feature의 value distribution에 대한 marginal model output을 나타냄높은 예측도를 위한 optimal feature value ranges를 확인하고자 Partial Dependence Plots (PDPs) 활용

- SHAP (SHapley Additive exPlanations): 유명한 XAI technique
Selecting Salient Features
- proxy model에 SHAP 적용 → IEA prediction을 위한 global feature importance를 구함
- features 선택 시 feature importance와 ease of tuning values 모두 고려함
- 명사와 동사만큼 형용사 또한 중요함을 알아냄
- 결론적으로 6개의 features를 선택함
- number of nouns (#nouns), the number of adjectives (#adjs), the number of verbs (#verbs), mean concreteness of nouns (conc_noun), mean concreteness of adjectives (conc_adj), mean concreteness of verbs (conc_verb)
Identifying Feature Value Ranges
- #adjs와 conc_adj에 대한 PDP를 구함

- feature value range(𝑥)를 알아냄
- model output: 𝑓 (𝑥) (= 해당 연구의 proxy model에 의해 높은 IEA를 예측할 확률)
Optimal feature values
- 텍스트 내 형용사의 개수 > 1
- 형용사들의 mean concreteness > 2.0
RUBRIC FOR AUTOMATIC PROMPT EDITING
- Rubrics

- 3가지 원칙에 따라 만들어짐
- key elements in images를 고려해 간결할 것
- element descriptions를 고려해 구체적일 것
- key context of the original text와 일치할 것
- contextual meaning in the description을 깨지 않기 위해 명사와 동사에 대해서는 word concreteness 대신 개수만 조정함
- 형용사를 추가하는 경우 ConceptNet에서 3개의 연관된 단어를 추가하도록 함
- Prompt editing process of RePrompt
- 주어진 텍스트 내 단어들에 대해 part-of-speech (POS)를 라벨링한 후, 명사, 동사, 형용사가 아닌 단어를 삭제함
- 단어와 full text with the emotion label appended 사이의 CLIP Score를 통해 word saliency를 계산함
- saliency order에 따라 어떤 단어를 삭제하거나 추가할 지 판단함
- ConceptNet에서 top-3 salient 형용사를 추가함
- 선행연구와 동일한 설정임
- required concreteness (>2.0)에 맞는 형용사 3개 선정
- emotion label을 추가해 prompt revision을 마무리 함
💡 RQ3: How effective is RePrompt at improving emotional expression in image generation?
- Simulation Study
- User Study
- → 생성된 이미지들의 품질을 비교
METRICS AND CONDITIONS
- 서로 다른 4가지 방식의 Prompt Editing Method 사이 비교
- Original Prompt, Manually Edited Prompt, Label Appended Prompt, RePrompt
- RQ1에서와 동일한 텍스트와 DALLE 2를 이용하여 이미지를 생성함

- Simulation Study: CLIP scores를 사용해 객관적으로 ITA & IEA 측정
- User Evaluation Study: 검증자들의 주관적인 점수를 이용해 ITA & IEA 측정
STATISTICAL METHODS
- LMER(linear mixed effects regression) models: on various dependent variables
- ANOVAs: on the fixed main and interaction effects
- post-hoc contrast tests: for the specific differences identified
- 비교 횟수가 많으므로 significance level을 strict하게 생각함
- differences with p < .001 : significant / p < .005 : marginally significant
SIMULATION STUDY
- CLIP Score를 계산하고 LMER models를 피팅함
- fixed main effect: Prompt Editing Method
- random effect: prompt ID


RESULTS
- IEA: Original Prompt보다 3가지 방식 모두 높은 IEA를 보여줌, 특히 RePrompt가 가장 높음
- ITA: RePrompt의 ITA가 낮아서, 텍스트의 내용이 바뀌었을 수 있음을 보여줌
- Label Appended가 높은 ITA score를 보였음에서 emotion labels가 기존 프롬프트와 높은 연관성을 가짐을 알 수 있음
IMAGE EVALUATION USER STUDY
- 사람들은 주관적이며, 이미지 속 감정을 서로 다르게 인식하기도 하므로 유저 스터디가 필요함
- 서로 다른 4가지 방식의 Prompt Editing Method 사이 비교
- 각 방식마다 DALLE 2에서 생성한 이미지 하나씩 랜덤 선택
- 146개의 이미지 그룹을 생성함
- 각 방식마다 DALLE 2에서 생성한 이미지 하나씩 랜덤 선택
PARTICIPANTS AND DATA COLLECTION
- 197명 (여성 48.2%, 19-72세) from Amazon’s Mechanical Turk
- 721명 중 사전 테스트를 통과한 참가자가 197명이었음 (27.2% 통과율)
- 소요 시간 평균 36.9분, 5달러 지급
PROCEDURE
- full survey는 부록의 Figure 13~26에서 확인 가능
- 유저가 emotional text와 이미지 쌍들을 평가함
- 사전에 영어 능력 평가 및 감정 지능 평가를 위한 테스트를 진행
- 해당 평가에서 만점인 참가자만이 이후 단계 진행 가능
- 각 피험자는 랜덤으로 선택된 15개의 텍스트와 이미지 그룹을 평가함
- 텍스트를 읽고 감정을 잘 반영하고 있는지 0-100으로 평가
- IEA를 고려하며 4개의 이미지를 보고 순위를 매김
- IEA를 고려하며 각 이미지를 0-100으로 평가
- IEA를 고려하며 평가 근거를 작성함 (해당 질문은 피험자의 피로도를 고려해 3회만 실시하였음)
- ITA를 고려하며 b~d 단계를 한 번 더 진행함
- 사전에 영어 능력 평가 및 감정 지능 평가를 위한 테스트를 진행
RESULTS OF RATINGS
- LMER models 피팅
- fixed main effect: Prompt Editing Condition / random effect: participant


- fixed main effect: Prompt Editing Condition / random effect: participant
- IEA: Original Prompt보다 3가지 방식 모두 높은 IEA를 보여줌, 특히 RePrompt가 가장 높으나 차이가 크지는 않음
- ITA: 놀랍게도 Original Prompt보다 3가지 방식 모두 높은 ITA를 보여줌
- Confounder analysis: 감정의 종류(ex. 긍정, 부정 등)가 많은 영향을 끼침을 파악
- LMER models를 수정함
- fixed main effect: Prompt Editing Condition + Emotion Type and its interaction


- fixed main effect: Prompt Editing Condition + Emotion Type and its interaction
- LMER models를 수정함
- interaction effect가 중요함을 확인할 수 있음
- negative emotions에서만 RePrompt images가 높은 IEA & ITA를 보임
- IEA rating에 대한 해석
- 평가자들이 positive emotions보다 negative emotions에 더 민감하게 반응했을 수 있음
- 선행 연구를 통한 support
- 인간은 negative 자극에 더 민감함
- 인간 진화론: 진화는 nervous system이 더 빠르고 강렬하게 반응하게끔 하였음
- 인간의 뇌는 survival mechanism으로써 이미지 처리를 위한 routes를 진화시켰음
- 선행 연구를 통한 support
- RePrompt가 positive emotions의 이미지 품질을 향상하지 못했음 (→기각)
- simulation study에 또 다른 LMER model을 fitting 함
- fixed main effect: Prompt Editing Condition + Emotion Type and its interaction
- simulation study에 또 다른 LMER model을 fitting 함
- CLIP Score가 positive emotions에 대한 인간 인지를 잘 모델링하지 못함
- Emotion6 dataset을 활용한 후속 연구
- 각 감정 라벨에 대한 CLIP Scores 계산
- CLIP Score와 각 감정 사이 Pearson r correlation 계산
- Emotion6 dataset을 활용한 후속 연구
- 평가자들이 positive emotions보다 negative emotions에 더 민감하게 반응했을 수 있음
- ITA rating에 대한 해석
- Simulation Study결과와 일치하지 않았음
- RePrompt에 따라 생성된 이미지는 original texts 의 key meanings을 유지했음
- 따라서 평가자들이 둘 사이 lack of alignment 를 발견하지 못하였음
- ITA에 대한 CLIP Score가 해당 케이스에 대해서는 인간의 인지를 반영하지 못하였음을 제안함
- 따라서 평가자들이 둘 사이 lack of alignment 를 발견하지 못하였음
- 평가자들의 ITA ratings 는 그들의 IEA ratings에 의해 영향을 받았음
- 둘 사이에는 강한 연관성이 있음 (Pearson r = 0.764, p < .0001)
- 설문조사에서 ITA rating questions가 IEA 이후에 나오므로 order effect의 가능성이 있음
- rating durations에 큰 차이가 있었음 (p < .0001)
- IEA ratings (M = 35.7 s) / ITA ratings (M = 27.4 s)
- 평가자들은 IEA ratings에 따라 ITA ratings을 하여, ITA rating에 있어서 less effort를 들였을 수 있음
- RePrompt에 따라 생성된 이미지는 original texts 의 key meanings을 유지했음
- Simulation Study결과와 일치하지 않았음
RESULTS OF RANKINGS
- 명확하게 드러나는 차이가 없었음
- Rating scores와의 연관성 또한 약하였음
- Rating scores보다 덜 sensitive하였음
CONCLUSION
- RePrompt: semanatic precision을 향상하기 위한 자동화된 텍스트 프롬프트 엔지니어링
- 생성형 AI모델이 더 나은 IEA를 갖는 이미지를 만들어내게끔 할 수 있었음
- 특히 negative emotions에 대한 경우 효과적
- 생성형 AI모델이 더 나은 IEA를 갖는 이미지를 만들어내게끔 할 수 있었음
'📑 Paper > 💌 Prompt Engineering' 카테고리의 다른 글
| A Taxonomy of Prompt Modifiers for Text-To-Image Generation (1) | 2023.11.22 |
|---|